

Enterprise Search
Why Search Scales Differently from Data or BI
Published: November 7, 2025
Share this post

Search box powered by AI is quickly becoming the new expectation for accessing enterprise data. However, interestingly, this search box can reside in multiple places: it can be right within the database platform where the data is stored, or in the BI tool where the dashboards are built, or be standalone like Tursio. In this blog, we discuss the scalability aspect with these different architectural choices.
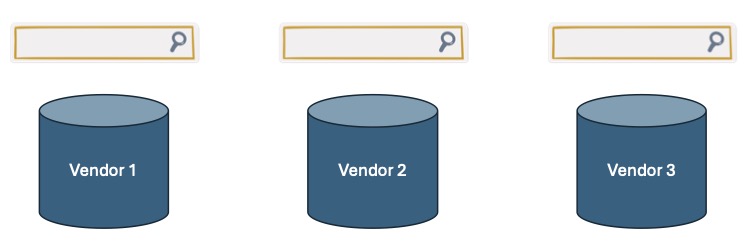
Enterprises have long faced the challenge of managing a growing maze of disconnected data sources. While data integration efforts have helped, introducing separate search interfaces for each system risks creating a new layer of complexity, something that could soon become a “search integration” problem.
A search application primarily orchestrates tasks like compiling queries, retrieving data, and generating responses. Since the generation itself happens via LLM APIs, the compute clusters used for search tend to be mostly idle with low utilization. This makes AI workloads fundamentally different from data workloads, with distinct infrastructure requirements, and therefore, it is better to disaggregate them.
Thus, on closer examination, scaling search within the database platform is challenging due to the creation of new silos, duplicated effort, and misaligned costs.

Scaling search with BI tools presents several challenges: dashboards are becoming quickly outdated, the data modeling step, required by most BI tools, is slow and labor-intensive, and the traditional unit economics based on user count are increasingly misaligned with the efficiency gains brought by modern AI.

In today’s enterprise landscape, users are less concerned with where the data resides or how it is modeled; they simply expect relevant answers. As data platforms continue to evolve, search should remain agnostic to these changes. Furthermore, the core purpose of data modeling is to provide the right context for meaningful search, and AI must increasingly take on the responsibility of inferring that context.
Natural language is now the standard for business interaction, with SQL becoming the new assembly language for executing backend operations, and data modeling being gradually absorbed into enterprise-wide knowledge graphs. These new realities require search to scale enterprise-wide by (i) connecting to all data without moving any of it, (2) inferring the knowledge graph without having people build it, and (3) providing high-quality search using the right context.
Tursio search platform has taken the above approach of scaling independent of databases and BI tools, and it supports all major databases and data warehouses. Ultimately, the goal is to help businesses run better while making people's lives easier.
Per-database Search
Running the search right within your database platform seems the right thing to do at first glance: push down the computations and minimize data movement. Not surprisingly, most database vendors are coming up with their own search capabilities, including Snowflake Cortex, Databricks Genie, Fabric Data Agent, or the recent acquisition of LibreChat by ClickHouse.New Silos
Unfortunately, enterprises typically operate with multiple databases at the same time. According to “The State of the Database Landscape” survey from Redgate, 79% of the IT teams are now using more than one database platform, with 29% of respondents using more than five. This means that running the search within the database platform would result in separate search interfaces for each platform, thus trapping search in the same silos that enterprise data is notorious for, as illustrated in the figure below:Enterprises have long faced the challenge of managing a growing maze of disconnected data sources. While data integration efforts have helped, introducing separate search interfaces for each system risks creating a new layer of complexity, something that could soon become a “search integration” problem.
Big Effort
Databases have traditionally been used by developers to store and query data. To support search capabilities, many vendors now offer additional constructs such as semantic views, verified query repositories, and custom instructions in platforms like Snowflake, or knowledge stores and sample SQLs in Databricks. However, enabling search still requires significant developer effort. Furthermore, this work often needs to be repeated across different database platforms, each with its own tools and learning curve. Training teams to build effective search experiences for each platform is challenging. Moreover, this effort can lead to vendor lock-in, making future migrations difficult since the semantic models and the context need to migrate as well.Growing Costs
Running AI-powered search within the data stack means using compute infrastructure originally designed for data processing to also handle search workloads. Interestingly, the actual AI inference is performed by foundation models, which are hosted separately and priced based on token usage; think of enterprise versions of OpenAI or self-hosted LLMs that are managed and scaled separately by governance teams.A search application primarily orchestrates tasks like compiling queries, retrieving data, and generating responses. Since the generation itself happens via LLM APIs, the compute clusters used for search tend to be mostly idle with low utilization. This makes AI workloads fundamentally different from data workloads, with distinct infrastructure requirements, and therefore, it is better to disaggregate them.
Thus, on closer examination, scaling search within the database platform is challenging due to the creation of new silos, duplicated effort, and misaligned costs.
Per-BI-tool Search
BI tools are not tied to a specific database, making them another viable option for running the search. It’s no surprise that most BI tools now offer search capabilities, including ThoughtSpot Spotter, Tableau Pulse, Power BI Copilot, and others. The figure below illustrates these approaches.Beyond Dashboards
Over the past couple of decades, business intelligence has been closely associated with building dashboards. However, dashboards are often limited to presenting numbers and charts, rather than delivering true insights, leaving it to business users to interpret the data. Additionally, organizations frequently accumulate too many dashboards, many of which are rarely viewed. As a result, there is a growing industry-wide push to move beyond traditional dashboards.Painfully Slow Step
BI tools typically require data modeling as a first step before building visualizations, reports, or search capabilities. This modeling process is often time-consuming and manual, sometimes involving complex data pipelines from database platforms. Large organizations frequently outsource data modeling and reporting to external consultants. However, with the growing demand for AI, scaling this slow and labor-intensive step to support search is becoming increasingly difficult.Unviable Unit Economics
BI tools have traditionally scaled based on usage, such as seats, queries, and similar metrics. This model assumes human hours as the core currency, mapping value directly to how many people are enabled to create, modify, or view dashboards. But what happens when productivity increases 10x, 100x, or more? If one person can now do the work of an entire BI team, should the company still pay for 100 seats? Scaling based on people is beginning to challenge the unit economics of the BI model.Scaling search with BI tools presents several challenges: dashboards are becoming quickly outdated, the data modeling step, required by most BI tools, is slow and labor-intensive, and the traditional unit economics based on user count are increasingly misaligned with the efficiency gains brought by modern AI.
Per-enterprise Search
Search should not be tied to database platforms or the BI tools; it should instead scale independently for the enterprise, as illustrated below.In today’s enterprise landscape, users are less concerned with where the data resides or how it is modeled; they simply expect relevant answers. As data platforms continue to evolve, search should remain agnostic to these changes. Furthermore, the core purpose of data modeling is to provide the right context for meaningful search, and AI must increasingly take on the responsibility of inferring that context.
Natural language is now the standard for business interaction, with SQL becoming the new assembly language for executing backend operations, and data modeling being gradually absorbed into enterprise-wide knowledge graphs. These new realities require search to scale enterprise-wide by (i) connecting to all data without moving any of it, (2) inferring the knowledge graph without having people build it, and (3) providing high-quality search using the right context.
Tursio search platform has taken the above approach of scaling independent of databases and BI tools, and it supports all major databases and data warehouses. Ultimately, the goal is to help businesses run better while making people's lives easier.
Related blog posts

Analyzing MCP Token Costs
MCP token costs depend more on architecture than on which LLM you pick — a comparative analysis and a forecasting tool to understand token costs better.
Akshara Mahalingam and Shivani Tripathi
Read more

The Context Structuring Problem
Enterprise AI is only as good as its context — but today that context is scattered across prompt files, skill markdowns, and ad hoc RAG pipelines that every team rebuilds from scratch.
Alekh Jindal
Read more

Making MCPs Practical with Context Pushdown
Traditional MCPs have a twist the moment you try to run them in production: they can be unreliable, expensive, and slow.
Shivani Tripathi, Wangda Zhang, Alekh Jindal
Read more
Bring search to your
workflows
workflows
See how Tursio helps you work faster, smarter, and more securely.


Data protection
'/%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_7851_102227'%20x1='0'%20y1='174.933'%20x2='1312'%20y2='174.933'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%231E4EC4'/%3e%3cstop%20offset='0.8'%20stop-color='%230D6EFD'/%3e%3cstop%20offset='1'%20stop-color='%235BC0EB'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)