

Databases
Generative AI
Why AI fails despite "great” models?
Published: September 19, 2025
Share this post

We’ve all seen the AI demos: someone types in a question, and an instant answer appears. The audience feels the wow and the presenter steals the show. Everyone leaves convinced that this is the next big thing. But in real life? That’s not how it works.
The gap between demo magic and real use is where most enterprise AI fails. In fact, recent report from MIT’s NANDA project reveals that 95% of the generative AI pilots are failing. This is intriguing, especially when the latest GPT models are now touted to possess PhD-level intelligence.
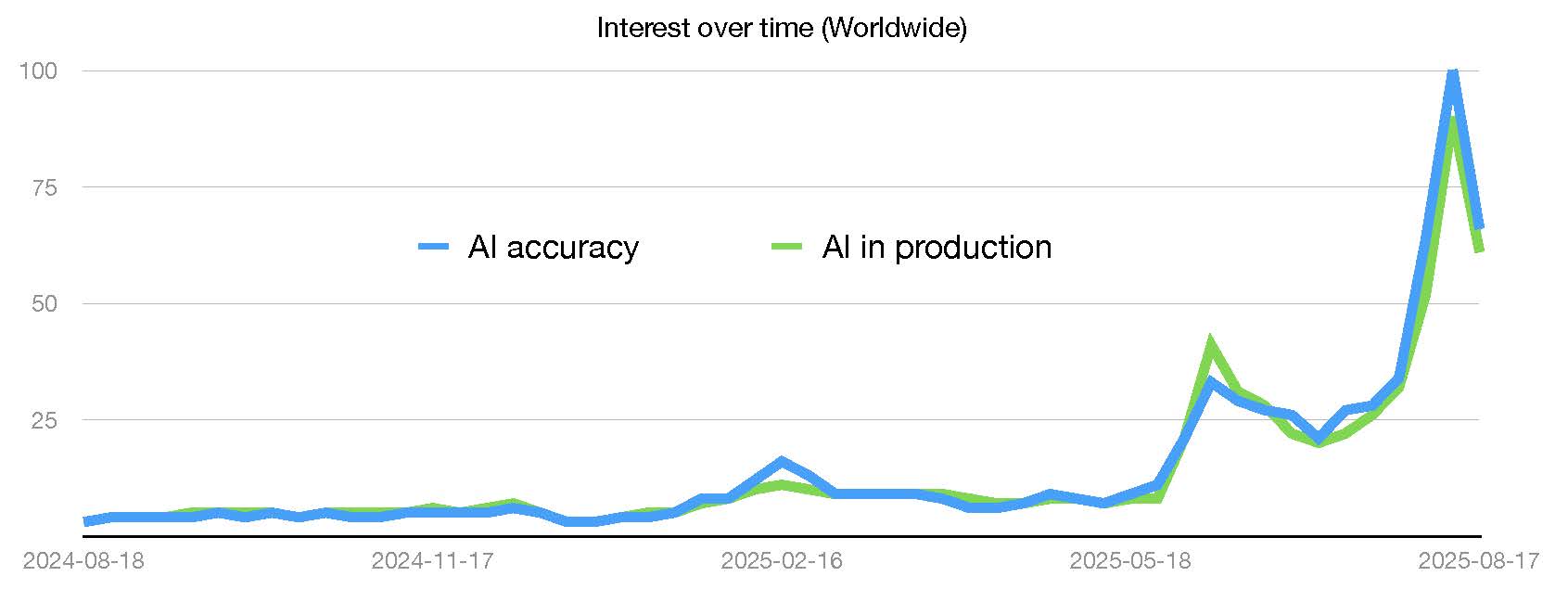
Considering Google Trends as a proxy, the graphic below shows the interest in "AI in production" over the last one year (green curve). We can see an astronomical rise in this topic in the recent months. Co-incidentally, this is matched, nearly pixel by pixel, by interest in "AI accuracy" (blue curve). Is this a mere co-incidence that people are suddenly interested in accuracy just as they are interested in getting AI to production?
Turns out that the best of the models are only as good as the prompts they get. In fact, studies suggest that only half the gains seen with more advance AI model come from the model itself, while the other half come from how users adapt their prompts. No wonder, GPT-5, like its predecessors, comes with an elaborate prompting guide instructing users how to prompt the model in different scenarios.
Here is the surprising truth for people disappointed with the answers to their questions: it's not the model's fault—it’s the question’s. The ability to ask the right question—with the right context, in the right format—is the single most overlooked skill in AI today, also referred to as prompt engineering. Unfortunately, most people don’t know how to prompt. And most tools aren’t built to help them.
To illustrate, here is the system prompt that powers the magic behind Claude, as released by Anthropic on August 5, 2025. This prompt is 2,560 word long and spans 6-pages, with detailed instructions about various types of questions that users may ask. The screenshot below shows just a snippet of this massive prompt:

Building such sophisticated prompts is near-impossible for regular users. While people can often start with simpler prompts, depending on their application, covering various corner cases makes them increasingly complex over time. In enterprise settings, where users are querying structured data, the stakes are higher, and the complexity is even deeper. Since you are not chatting about movie ideas but rather making decisions based on what’s inside complex enterprises databases, the ability to get what’s needed quickly and accurately is paramount. Prompting such data requires a good understanding of the structure, the underlying semantics, the business context, and crafting all that into the right prompts for the AI – clearly, a tall ask for most users.
So, here is the typical user behavior today: Users either freeze at the prompt box or spiral into 10+ turns of trial-and-error chats, only to give up with mediocre output. When prompts are vague or misaligned with the data, you get hallucinations, non-answers, or worse: confident lies. That’s a fast track to lost trust.
The new age AI tools are incredibly hard to control without the prompt perfectionism. We are trying to avoid prompts that are ambiguous or vague, prompts that are confusing or have contradictory instructions, prompts requesting unknown or unsupported facts, prompts that are long, overly broad, or multi-faceted, prompts lacking retrieval or grounding (citations), prompts that “jailbreak” the model on safety and truthfulness, prompts that are adversarial or misleading, and the list goes on. In short, we are clearly not talking to another human anymore, but trying to operate Formula 1 machines with tricycle training. And this is where even technically savvy users struggle to translate what they want into a precise, semantically valid, data-aware prompts. That’s not just inefficient. It’s dangerous—because it creates a false sense of reliability.
What’s really broken? Well, most enterprise users are asked to learn the art of prompting and to start doing it from scratch. There’s no autocomplete. No query validation. No semantic hinting. We’ve created an illusion of power, where users can "ask anything", while at the same time we ask users to reinvent the wheel every time. And this design flaw doesn’t just create friction. It kills momentum.
Given the complexities in enterprise data, treating prompting like typing in a search box ends up being a non-starter. Prompting for data is a dynamic process that needs scaffolding. While expert data users might be able to muddle through, users in ops, marketing, or finance are likely to flounder. Essentially, we are locking knowledge behind an interface that pretends to be simple—but isn’t.
What exists? Asking questions on the data has the implicit assumption that the answers will come only from the data. This is often tedious since either the questions are too far from whats exists in the data or the responses are hallucinated to make things up. Discovering what exists in the data can help the users frame their questions more accurately and set better expectations for the responses.
What's meaningful? Data operations need to be meaningful with respect to the underlying data properties. Combining customers and employees that have no join relationship between them will yield garbage responses. Likewise, counting patients without deduplicating them on their IDs or summing up ages instead of averaging them is rarely meaningful. Identifying and navigating users through such data properties can help improve the correctness.
What's probable? SQL is grounded in first-order logic, i.e., predicates and quantifiers on sets. Unfortunately, this is not so intuitive to people when they are trying to ask data queries in natural language, that will ultimately get translated to SQL statements. Guiding users through the probable predicates and quantifiers while also limiting them from anything that could not be operated on sets can help ground the expectations.
Essentially, the Auto mode is like working inside a smart IDE for queries. The intended experience is to feel like "vibe coding", i.e., you explore, select, and accept. The system fills in the gaps. Eventually, the goal is to make Tursio accessible to non-experts and they can forget the underlying SQL even existed.
A natural reaction to this counterintuitive solution could be to just teach prompting: "But people just need training". Maybe. But most people aren’t prompt engineers—and they shouldn’t have to be. We believe AI tools should adapt to humans, not the other way around. This isn’t about dumbing down the AI. It’s about removing friction so people can get real work done.
The gap between demo magic and real use is where most enterprise AI fails. In fact, recent report from MIT’s NANDA project reveals that 95% of the generative AI pilots are failing. This is intriguing, especially when the latest GPT models are now touted to possess PhD-level intelligence.
Considering Google Trends as a proxy, the graphic below shows the interest in "AI in production" over the last one year (green curve). We can see an astronomical rise in this topic in the recent months. Co-incidentally, this is matched, nearly pixel by pixel, by interest in "AI accuracy" (blue curve). Is this a mere co-incidence that people are suddenly interested in accuracy just as they are interested in getting AI to production?
Turns out that the best of the models are only as good as the prompts they get. In fact, studies suggest that only half the gains seen with more advance AI model come from the model itself, while the other half come from how users adapt their prompts. No wonder, GPT-5, like its predecessors, comes with an elaborate prompting guide instructing users how to prompt the model in different scenarios.
Here is the surprising truth for people disappointed with the answers to their questions: it's not the model's fault—it’s the question’s. The ability to ask the right question—with the right context, in the right format—is the single most overlooked skill in AI today, also referred to as prompt engineering. Unfortunately, most people don’t know how to prompt. And most tools aren’t built to help them.
The current state: Prompting is a tedious art
Today’s LLM tools expect users to behave like prompt engineers. The common guidance is to "just ask it like you would a human". But that’s easier said than done and the reality is, how you prompt matters immensely, and most AI tools do very little to help you prompt better.To illustrate, here is the system prompt that powers the magic behind Claude, as released by Anthropic on August 5, 2025. This prompt is 2,560 word long and spans 6-pages, with detailed instructions about various types of questions that users may ask. The screenshot below shows just a snippet of this massive prompt:
Building such sophisticated prompts is near-impossible for regular users. While people can often start with simpler prompts, depending on their application, covering various corner cases makes them increasingly complex over time. In enterprise settings, where users are querying structured data, the stakes are higher, and the complexity is even deeper. Since you are not chatting about movie ideas but rather making decisions based on what’s inside complex enterprises databases, the ability to get what’s needed quickly and accurately is paramount. Prompting such data requires a good understanding of the structure, the underlying semantics, the business context, and crafting all that into the right prompts for the AI – clearly, a tall ask for most users.
So, here is the typical user behavior today: Users either freeze at the prompt box or spiral into 10+ turns of trial-and-error chats, only to give up with mediocre output. When prompts are vague or misaligned with the data, you get hallucinations, non-answers, or worse: confident lies. That’s a fast track to lost trust.
The problem: Garbage in, garbage out
The bottleneck in enterprise AI isn't the AI — it is the human input.The new age AI tools are incredibly hard to control without the prompt perfectionism. We are trying to avoid prompts that are ambiguous or vague, prompts that are confusing or have contradictory instructions, prompts requesting unknown or unsupported facts, prompts that are long, overly broad, or multi-faceted, prompts lacking retrieval or grounding (citations), prompts that “jailbreak” the model on safety and truthfulness, prompts that are adversarial or misleading, and the list goes on. In short, we are clearly not talking to another human anymore, but trying to operate Formula 1 machines with tricycle training. And this is where even technically savvy users struggle to translate what they want into a precise, semantically valid, data-aware prompts. That’s not just inefficient. It’s dangerous—because it creates a false sense of reliability.
What’s really broken? Well, most enterprise users are asked to learn the art of prompting and to start doing it from scratch. There’s no autocomplete. No query validation. No semantic hinting. We’ve created an illusion of power, where users can "ask anything", while at the same time we ask users to reinvent the wheel every time. And this design flaw doesn’t just create friction. It kills momentum.
Given the complexities in enterprise data, treating prompting like typing in a search box ends up being a non-starter. Prompting for data is a dynamic process that needs scaffolding. While expert data users might be able to muddle through, users in ops, marketing, or finance are likely to flounder. Essentially, we are locking knowledge behind an interface that pretends to be simple—but isn’t.
The counterintuitive solution: Auto mode
Most people don’t need a "chatbot". They need a smart assistant that scaffolds their thinking. That’s why at Tursio, we built the Auto Mode: a new way to prompt based on what exists, what’s meaningful, and what’s probable—all grounded in your data. Let's unpack each of these below:What exists? Asking questions on the data has the implicit assumption that the answers will come only from the data. This is often tedious since either the questions are too far from whats exists in the data or the responses are hallucinated to make things up. Discovering what exists in the data can help the users frame their questions more accurately and set better expectations for the responses.
What's meaningful? Data operations need to be meaningful with respect to the underlying data properties. Combining customers and employees that have no join relationship between them will yield garbage responses. Likewise, counting patients without deduplicating them on their IDs or summing up ages instead of averaging them is rarely meaningful. Identifying and navigating users through such data properties can help improve the correctness.
What's probable? SQL is grounded in first-order logic, i.e., predicates and quantifiers on sets. Unfortunately, this is not so intuitive to people when they are trying to ask data queries in natural language, that will ultimately get translated to SQL statements. Guiding users through the probable predicates and quantifiers while also limiting them from anything that could not be operated on sets can help ground the expectations.
Essentially, the Auto mode is like working inside a smart IDE for queries. The intended experience is to feel like "vibe coding", i.e., you explore, select, and accept. The system fills in the gaps. Eventually, the goal is to make Tursio accessible to non-experts and they can forget the underlying SQL even existed.
A natural reaction to this counterintuitive solution could be to just teach prompting: "But people just need training". Maybe. But most people aren’t prompt engineers—and they shouldn’t have to be. We believe AI tools should adapt to humans, not the other way around. This isn’t about dumbing down the AI. It’s about removing friction so people can get real work done.
Final thoughts
Every new wave of technology goes through a cycle of hype followed by grounding. AI is no different with many AI tools already entering the grounding phase. Prompting has been a revelation in this process, as people quickly realize it to be both an art and a science. Consequently, more mature AI tools now abstract complex parts of prompts into system and developer layers, requiring minimal to no prompting from users. Tursio takes this a step further by introducing auto-prompting for data, hiding the complexities of data prompts so users no longer have to worry about them. Ultimately, the goal is to make data simpler and to get the job done.Related blog posts

Analyzing MCP Token Costs
MCP token costs depend more on architecture than on which LLM you pick — a comparative analysis and a forecasting tool to understand token costs better.
Akshara Mahalingam and Shivani Tripathi
Read more

The Context Structuring Problem
Enterprise AI is only as good as its context — but today that context is scattered across prompt files, skill markdowns, and ad hoc RAG pipelines that every team rebuilds from scratch.
Alekh Jindal
Read more

Making MCPs Practical with Context Pushdown
Traditional MCPs have a twist the moment you try to run them in production: they can be unreliable, expensive, and slow.
Shivani Tripathi, Wangda Zhang, Alekh Jindal
Read more
Bring search to your
workflows
workflows
See how Tursio helps you work faster, smarter, and more securely.


Data protection
'/%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_7851_102227'%20x1='0'%20y1='174.933'%20x2='1312'%20y2='174.933'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%231E4EC4'/%3e%3cstop%20offset='0.8'%20stop-color='%230D6EFD'/%3e%3cstop%20offset='1'%20stop-color='%235BC0EB'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)