

Context Pushdown
Making MCPs Practical with Context Pushdown
Published: April 24, 2026
Share this post

The quick rise
Anthropic launched the Model Context Protocol (MCP) in November 2024 as an open standard for connecting AI assistants to backend systems. A year later, it is everywhere. The MCP Registry lists close to two thousand servers, up 400% from its launch batch in September. OpenAI, Google, Microsoft, AWS, GitHub, Salesforce, Cloudflare, and dozens of others have shipped their own servers or client support. In December 2025, Anthropic donated the protocol to the Linux Foundation.The appeal is easy to see. Before MCP, every agent needed a custom connector for every tool, essentially an N×M problem. MCP collapsed that to N+M: a service builds one server, and any MCP-aware agent can use it. The resulting spec is small, with an open SDK that developers can get working in an afternoon. That low barrier, plus the network effect of major vendors jumping in early, is what turned it into a de facto standard so quickly.
A Pandora's box
MCPs have a twist the moment you try to run them in production. The most visible cost is tokens. Anthropic's own engineering team reported agents burning 150,000 tokens just to load tool definitions before the model had read a single word of the user's request, and in their published example, tool definitions and intermediate results could consume 50,000+ tokens on a routine task. This means that context windows will be half-spent simply by connecting a handful of servers even before the work begins.Tokens are just the entry fee. Reliability drifts because the same question answered by two different agents, or by the same agent on two different days, takes different paths through the schema and returns subtly different results. This compounds the latency since every intermediate payload passes through the model on its way to the next tool call. Furthermore, Agents get confused when two servers expose similarly named tools, or when a tool description is ambiguous enough that the model picks the wrong one. To address this, teams end up writing long, fragile instruction prompts, which themselves eat more tokens.
Struggling for the context
Let's step back and look at what a typical data-source MCP server exposes. Basically, it does two things: describes schemas and runs queries. Everything else is left to the agent to work out at runtime and every time, including which tables are relevant, what the join keys are, which column holds the revenue number versus the forecast, and whether "customer" means account or end-user in this schema. So the agent lists schemas, reads column names, guesses at relationships, runs a probe query, reads the sample, corrects its guess, runs another query, and eventually answers the question. The reasoning is real work, and the model is genuinely good at it. The problem is where that work lives.
That reasoning is redone from scratch on every query, by every agent, every time. Ask "what was revenue last quarter" on Monday, and the agent figures out that revenue lives in fact_orders.net_amount, filtered by order_status = 'shipped', grouped by fiscal_quarter from dim_date. Ask the same question on Tuesday, and it starts over. A second agent asks a related question and arrives at a slightly different answer because it picked gross_amount instead. A third tries, fails on a join it didn't know was needed, retries with a different guess, and eventually lands somewhere plausible.
Unfortunately, we end up with inconsistent results across agents and across time. Also, the cost per query is high because each run re-pays the exploration tax. Latency is bad because the work is serial: read schema, think, query, read, think, query, and so on. And when a probe returns something the agent didn't expect, it often falls into a retry loop until it times out or stumbles onto an answer that looks right.
Towards context pushdown
Tursio's approach is to do the above reasoning once, persist it as a context graph, and reuse it. The schema, the relationships, the meaning of each field, the known-good query patterns, essentially everything an agent would otherwise rediscover on every call, are captured as the context graph that sits in front of the data source. Every agent, and every query from every agent, runs against the same graph. Consequently, the agent's job shrinks: instead of exploring and guessing, it asks the graph and gets back an answer grounded in vetted context. The graph is a shared, versioned artifact, not a prompt or a per-agent instruction blob.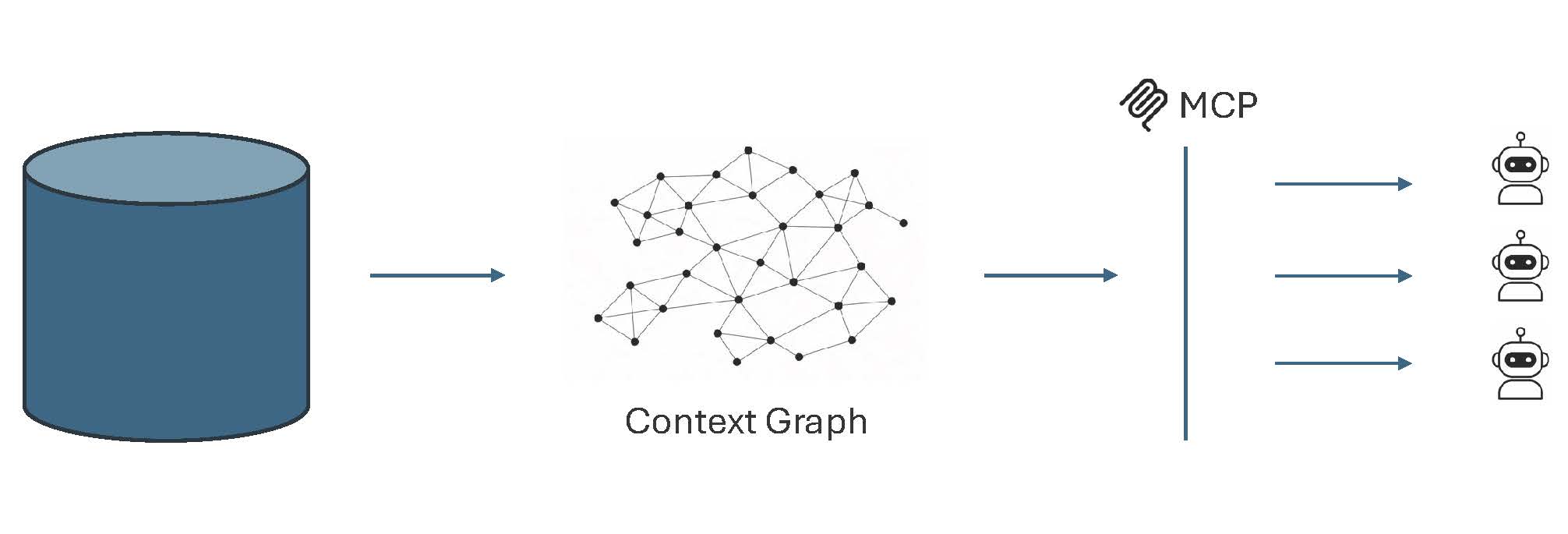
The payoff is clear in this design. Answers are consistent because every agent reasons against the same stabilized context: Monday's revenue query and Tuesday's return the same number because they resolve through the same definitions. Where the raw schema is ambiguous or a term has business meaning that the model can't infer, a human curates it once in the graph, and every agent benefits. Agents do less work, so they use fewer tokens and respond faster. And because the context lives in one place, an organization can govern it like any other shared asset: review what's exposed, monitor what gets queried, evolve definitions as the business changes, and fix a bad answer once instead of patching it across every agent that might ask.
Evaluating the benefits
We conducted a detailed evaluation of context pushdown on SQL Server. We initially considered the official SQL MCP Server as a baseline; however, it requires submitting queries through the Data API Builder (DAB), which is restrictive and does not support querying arbitrary SQL. Therefore, we used an Azure MSSQL Database MCP Server implementation as the baseline. Note that this implementation only supports local connections, so we submitted a PR to the Azure repo to add a streamable HTTP endpoint for remote agents to connect.
In this evaluation, we focused on querying a synthetic banking dataset, using OpenAI's Responses API as the MCP client. The dataset covers member engagement, digital banking utilization, and account lifecycle management, with a schema that spans everything from individual login events to high-level organizational trends. We tested both direct questions (factual queries starting with "how many," "list," "what") and open-ended ones (high-level questions with no fixed answer), running each query multiple times to measure consistency alongside correctness.
We evaluated the MCP performance with the following metrics, assessing not only whether the chat agent could answer a question well, but also how efficiently it got there:
- Response Quality (Correctness and Consistency)
- Efficiency and Cost (Agent Token Consumption, Execution Latency, Tool Call Count)
Vs. Out-of-the-box SQL Server MCP
The out-of-the-box Azure MSSQL MCP implementation provides tools for describing the database and tables, and for running SQL queries. Agents like ChatGPT need to use these tools to explore the database context and formulate queries. In contrast, Tursio's MCP with context pushdown eliminates the need to repeatedly discover context on the fly, achieving higher response quality, lower token consumption, and better response latency.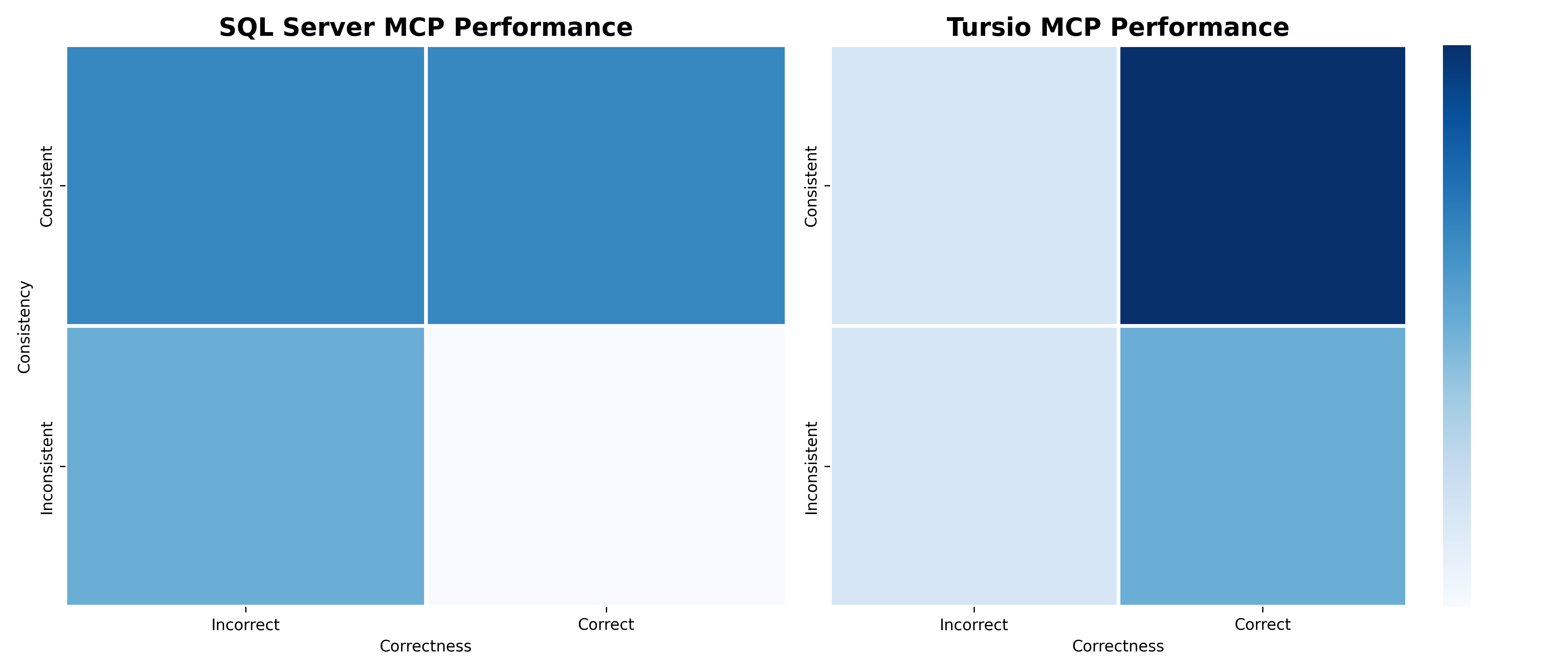

Across all metrics, namely correctness, consistency, tokens, latency, and tool calls, Tursio MCP consistently outperformed the baseline SQL Server MCP. Because of context pushdown, Tursio MCP consumed roughly 25% of the tokens that SQL Server MCP used, translating to lower costs and faster responses.
Furthermore, we noticed that SQL Server MCP performance degraded significantly when moving from structured direct queries to open-ended generic ones. Tursio maintained a much more stable and efficient performance profile regardless of question complexity.
Vs. Improved SQL Server MCP
Digging deeper into why the out-of-the-box SQL Server MCP underperformed, we traced part of it to a bug in the table-description tool and submitted another PR to fix it upstream. We also expanded the evaluation dataset with more direct questions — ones that SQL Server MCP handles best — to give it a better chance.


Takeaway
Related blog posts

Context Tuning for Enterprise Data
Context is the most valuable commodity in enterprise AI, Tursio combines automatic inference with business artifacts and people's knowledge to make it usable.
Read more

Structured Data Search
Structured data search lets anyone query operational databases, warehouses, and business systems in natural language right where the data lives.
Read more

Analyzing MCP Token Costs
MCP token costs depend more on architecture than on which LLM you pick — a comparative analysis and a forecasting tool to understand token costs better.
Read more
Bring search to your
workflows
workflows
See how Tursio helps you work faster, smarter, and more securely.


'/%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_7851_102227'%20x1='0'%20y1='174.933'%20x2='1312'%20y2='174.933'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%231E4EC4'/%3e%3cstop%20offset='0.8'%20stop-color='%230D6EFD'/%3e%3cstop%20offset='1'%20stop-color='%235BC0EB'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)