

nl2sql
query-complexity
How far are NL and SQL in NL2SQL?
Published: February 5, 2026
Share this post

Business vs Tech Users
SQL has traditionally been the language for data experts, alienating business users from the data. However, with rapid progress in large language models (LLMs), translating natural language questions from business to SQL, i.e., NL2SQL, is getting increasingly popular. Turns out that business questions are often high-level and do not have a simple SQL translation. Answering such high‑level questions over complex data is hard since the system must map the business user intent to the right tables, joins, filters, and metrics without losing meaning.High‑level queries sound simple (e.g., “what insights can you glean from our data?”) but they implicitly encode many decisions:
- Which entities should be queried (e.g., products, categories, regions)
- What time granularity applies (daily, weekly, monthly)
- How related tables should be joined
- Which metrics define concepts like insights
- Which business rules or filters must be applied consistently
At Tursio, our goal is to bridge this gap reliably. We interpret intent, resolve ambiguity, and generate accurate queries by selecting the right entities, joins, filters, and metrics. We answer all the questions accurately and consistently even when the schema is large and complex.
This blog summarizes our evaluation of natural language questions against structured databases, with a specific focus on identifying and characterizing queries that are high‑level.
To understand real‑world query behavior, we evaluated natural language questions sourced from production logs. Specifically, we considered 250 questions from non-Tursio users across different database sizes.
Why high-level questions?
Business users do not understand the underlying data, i.e., which tables and columns are present, what do they mean, how are they connected, and so on. As a result, their questions are often missing schema-specific details needed to interpret and answer them correctly. For example, business users often omit:- Explicit table or entity references
- Join paths
- Filter conditions
- Metric definitions
Consequently, these high-level questions require the system to infer a large amount of implicit information.
Question-SQL Distance
We now discuss two approaches for measuring the gap between question and their corresponding SQLs.Embedding-based Approach
The obvious choice for measuring question-SQL is to compute the semantic similarity between them. We used text-embedding-ada-002 model to generate text-embeddings and cosine distance to capture the similarity and consider two kinds of text vectors.
1. User question and LLM-generated question for corresponding SQL:
For every SQL corresponding to the user question, we use LLM to re-generate the question that SQL answers the best, using the following prompt:

We evaluated it for the 250 questions from Tursio production logs. The results are as follows:
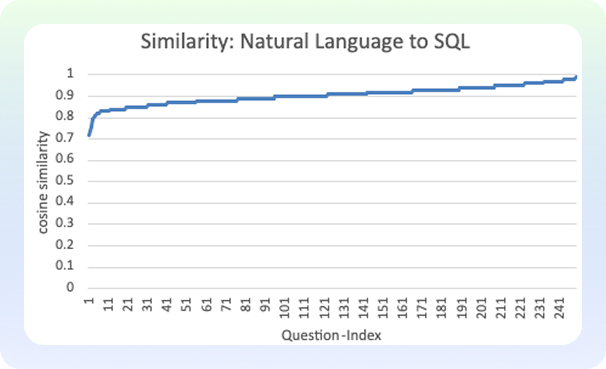
The similarity ranges from 0.7 to 1.0, indicating there is some variation. Yet it is hard to draw any conclusion here.
2. User question and the description generated for the SQL:
Re-generating questions from SQLs resulting in compact pieces of text that may not capture the nuances fully. Therefore, we also consider generating a more verbose description of the SQL using the following prompt:

The new result shows a minor change in the overall similarity range, but still most questions are densely packed on the similarity score, and it is hard to make any useful conclusion.
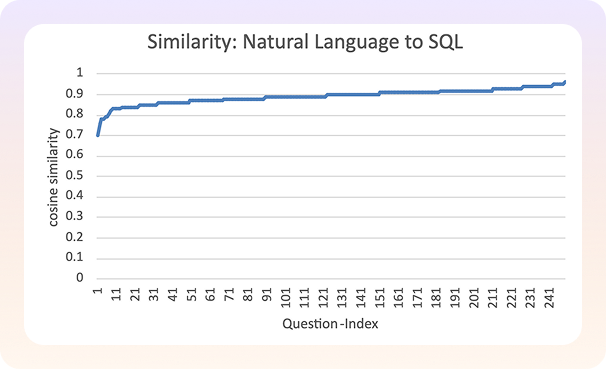
Token-Based Approach
Embedding models often suffer from crowding, with most vectors ending up in a dense cluster and a relatively small region of the vector space. Therefore, unless they are tuned well for the specific domain, it is hard to use them out of the box.To overcome this problem, we consider a simpler heuristic comparing the length of the natural language query and the length of the corresponding SQL. The questions which are short, but the SQL generated is long, hints towards missing details of the schema in the query. Conversely, questions that explicitly mention entities, filters, or schema concepts tend to map to shorter, more direct SQL and indicate low‑level questions, as they encode more implementation details.
We evaluated the above length-based heuristics to compare the distance between question and SQL. However, instead of using raw character length, we compare the tokens in the two strings, i.e., the units of text as seen by the model. The figure below shows the ratio of the length of SQL tokens to the question tokens for the production Tursio logs:

We can see the token ratio flat and closer to 1 for three-fourth of the questions, but the remaining questions have a steep rise in their token ratios. A large positive difference indicates that a short, high-level question expands into a long and complex SQL query, suggesting higher abstraction. We verified this by checking those questions in the Tursio logs manually.
NL2SQL Benchmarks
We now extend the above token ratio analysis to popular open-source benchmark datasets BEAVER (121 questions from DW warehouse; 88 questions from NW warehouse) and BIRD (1534 questions across 11 databases of varying sizes).The ratio of the length of SQL to question for BIRD and BEAVER benchmarks are as follows:

We can see that the ratio curve is flat and close to one for most questions in BIRD. Only a handful of questions have higher token ratios. This conforms with the broader community observation that BIRD benchmark has simpler questions that are more suitable for literal translation.
In fact, the BEAVER benchmark makes this precise argument and tries to model a more realistic query workload. The figures below show the token ratios of queries in BEAVER’s DW and NW warehouses.


Indeed, we can see that the token ratios of BEAVER are higher with a steeper curve compared to BIRD. Specifically, the questions in the NW warehouse are more high-level than other benchmarks.
Thus, the token-based approach is simple yet effective in identifying questions as either low-level, i.e., involving literal translation, or high-level, i.e., involving business semantics.
Summary
To summarize, NL2SQL is a misnomer for high-level business queries, which require far more understanding than a literal translation from natural language to SQL. Both our production logs and realistic public benchmarks show that these queries involve significantly greater SQL complexity, clearly distinguishing them from traditional NL2SQL tasks. In practice, business users don’t want to interact with SQL at all, and modern AI systems are expected to go beyond translation and take on that complexity on their behalf.Related blog posts

Analyzing MCP Token Costs
MCP token costs depend more on architecture than on which LLM you pick — a comparative analysis and a forecasting tool to understand token costs better.
Akshara Mahalingam and Shivani Tripathi
Read more

The Context Structuring Problem
Enterprise AI is only as good as its context — but today that context is scattered across prompt files, skill markdowns, and ad hoc RAG pipelines that every team rebuilds from scratch.
Alekh Jindal
Read more

Making MCPs Practical with Context Pushdown
Traditional MCPs have a twist the moment you try to run them in production: they can be unreliable, expensive, and slow.
Shivani Tripathi, Wangda Zhang, Alekh Jindal
Read more
Bring search to your
workflows
workflows
See how Tursio helps you work faster, smarter, and more securely.


Data protection
'/%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_7851_102227'%20x1='0'%20y1='174.933'%20x2='1312'%20y2='174.933'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%231E4EC4'/%3e%3cstop%20offset='0.8'%20stop-color='%230D6EFD'/%3e%3cstop%20offset='1'%20stop-color='%235BC0EB'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)