

Engineering
Generative AI
Generating Insights on Private Data
Published: May 19, 2023
Share this post

Back To the Future
In 1770, Wolfgang von Kempelen built the Mechanical Turk that gave the illusion of a machine playing chess. He was inspired by illusion acts in the court of Maria Theresa of Austria. 142 years later, in 1912, Leonardo Torres y Quevedo built El Ajedrecista, the first chess automaton that did not require human guidance. Two and a half decades later, in 1936, Alan Turing introduced the Turing Machine, which was capable of implementing any computer algorithm. In 1945, Alan Turing predicted that computers would play very good chess one day.
Later in 1951, 72 years ago, the first successful AI programs could play the complete game of Checkers and learn to do shopping. Checkers was also the first AI application to run in the US, with extensions to make it learn from experiences, i.e., evolutionary. “Machine learning” was coined in 1959 by Arthur Samuel, followed by decades of scientific progress in building machines that learn. The first chatbot, ELIZA, appeared in 1966, and Stanford Cart was the first autonomous vehicle in the 60s and 70s.
By the 1970s, the questions evolved from can machines think to can machines talk, with people wondering whether natural language is unnatural for machines, and one of the earliest natural language database systems, the English querying system (EQS), was developed at MIT. All of these were signs of incredible possibilities with groundbreaking starts. However, they were still early experiments confined to labs and prototypes in elite institutions.
Welcome To the Present
Today, we have come a long way with ChatGPT, estimated to have crossed 1 billion users! AI is no longer science fiction or the Tin Man from the Wizard of Oz, but a modern workable tech that everyone wants to play with and build upon. Moreover, it is encouraging to see the exciting AI landscape out there, with ChatGPT, Llama, Dolly, Bard all competing for the users’ mindshare. The language models have unleashed the creativity of the masses, like the internet or the mobile, and there is a global movement to rebuild pretty much everything we see in our world today. So much that researchers believe a 50% chance of human-level AI before 2061.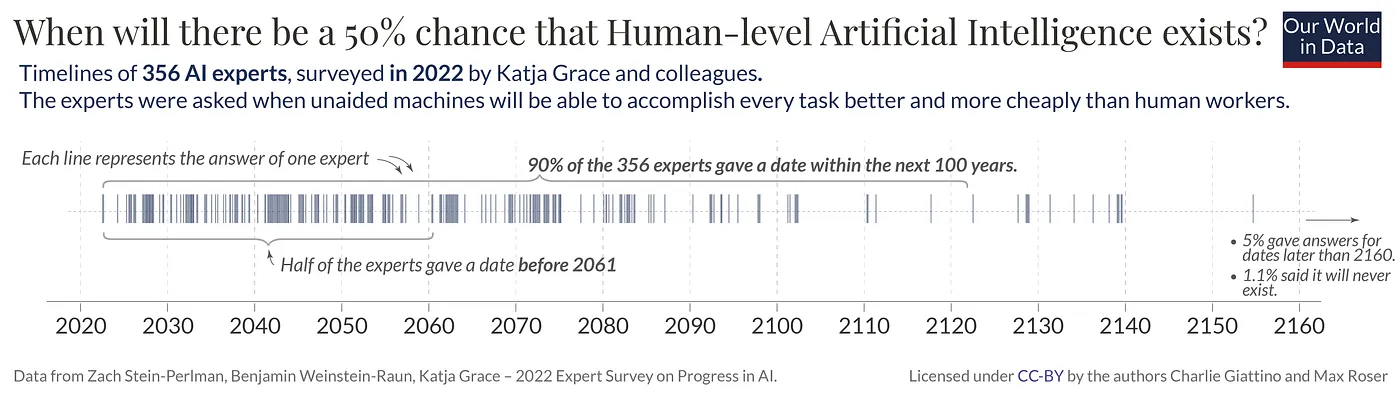
Source: https://ourworldindata.org/ai-timelines
This optimism is a golden opportunity for people working on data systems in two ways (1) More usage: advances in AI have simplified the interfaces to complex systems, making them accessible to everyone in natural language, and (2) New usage: there is an explosion of applications that surface data in interesting ways, thus creating newer scenarios and workloads. Altogether, data systems people are due for some exciting times, and they should brace up for that.
Generative AI for Data Applications
At SmartApps, we are pushing to create the best-in-class generative AI experience for modern data applications. We came up with the idea of “large data model” (LDM) that learns how to transform data in a data warehouse, and presented PikePlace, which is pre-trained over Snowflake data marketplace. Our LDM has already trained over 125M data models and generates lightning-fast insights (6ms-200ms) over a variety of datasets, including real estate, Covid-19, economy atlas, workforce, consumer engagement, vendor analytics, e-commerce, housing, web ads, Crunchbase, GitHub, and IPL. LDM helps transform data in these warehouses into high-quality data models for business applications; more importantly, however, LDM-generated data models are guaranteed to be correct and fast, i.e., the business users can rely on them consistently.
We now look to push the envelope further and use LDM to generate insights on private data, i.e., bring the same correctness and speed of generated data models to any given data source. Thanks to the big data movement of the last decade, every organization today has volumes of data collected into its data lake, and later extracted and ingested into its data warehouses. Yet, up to 97% of business data sits unused by organizations, thus missing tremendous business value to be unlocked. The right tools can transform such data into insights that could be useful. This is where LDM can help by:
- Reducing the grunt work in identifying typical data patterns (most likely ways to join, group, aggregate, etc.).
- Automating boilerplate SQL queries, data cleaning rules, and visualizations on different databases.
- Pruning the search space of data models to a small, meaningful one that can be explored visually.
- Providing a quick overview of what’s in the data and surfacing things that people may have otherwise missed.
- Allowing people to declare or specify what kind of data models they want before operationalizing them.
- Giving a good starting point to generate more ideas on how to analyze data for the problem at hand.
- Enabling data teams to do more with fewer resources and empowering non-experts to self-serve in many scenarios.
Introducing SanJuan: LDM on Private Data
Today, we announce SanJuan, our next version of generative analytics that applies the “large data model” (LDM) to private data files. With as many as 750 million to 2 billion people in the world using either Excel or Google Sheets, data files are all around us, but they are often disorganized and tedious to run traditional data analytics on. Data files are also the de facto input/output for data scientists, with CSV and Excel formats being supported by all popular data science libraries. SanJuan allows users to generate insights over their data files in three simple steps:
- Login. Users log in using standard authenticators (Google authenticator supported currently), and all their information is visible only to them.
- Upload. Once logged in, users can upload CSV or Excel files. They can upload multiple files, each up to 10MB in size, which get stored in a dedicated Snowflake database for each account. A background job runs the LDM inference on newly uploaded files every 20 minutes, which is also the length of an average coffee break.
- Analyze. Once the user is back from a coffee break, they can refresh the page and start analyzing models and visualizations that are automatically generated on their private data files.
Voila! The above three steps get your data files talking to you visually!
Scenarios
Let’s look at some of the interesting scenarios that we have come across.
Rideshare
Ride share companies like Uber and Lyft are looking to analyze patterns of their usage and find opportunities to improve their services. Using SanJuan on a sample rideshare dataset from Boston can help discover interesting insights, such as most rides take place in cloudy weather, Uber gets 54% of the rides while Lyft gets 46%, and Financial district is the least popular destination while Northeastern university is the most popular.

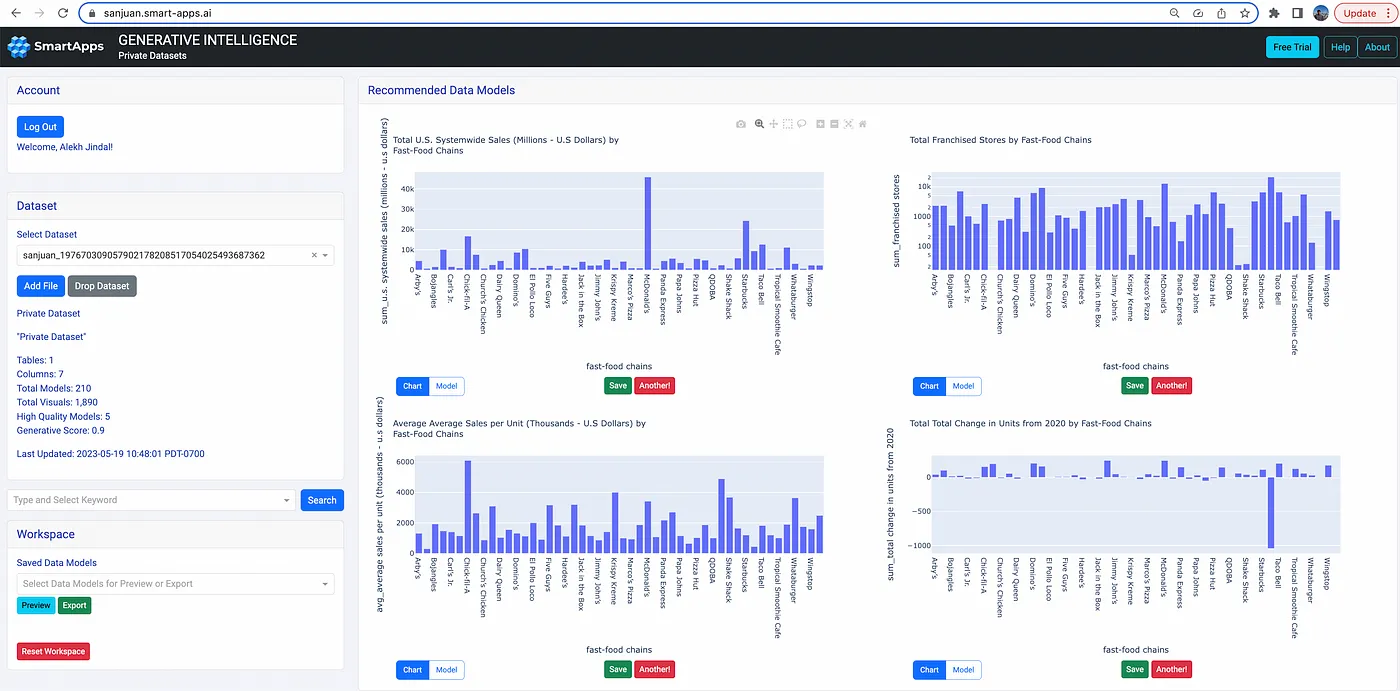
Fast Food Chains
The fast-food industry is very big, and analysts are constantly looking for ways to boost sales. SanJuan can quickly show insights on this sample dataset on top-50 fast food chains in the USA. For example, Chick-fil-A is #3 after Starbucks and McDonald’s in terms of total sales, but it has the highest average sales per unit in the U.S. Or, Jersey Mike’s added the maximum number of stores while Subway lost the maximum number of stores since 2020. These generated insights can save a lot of time for data scientists who may otherwise end up doing a lot of grunt work in building a long and verbose Notebook for the same data set.
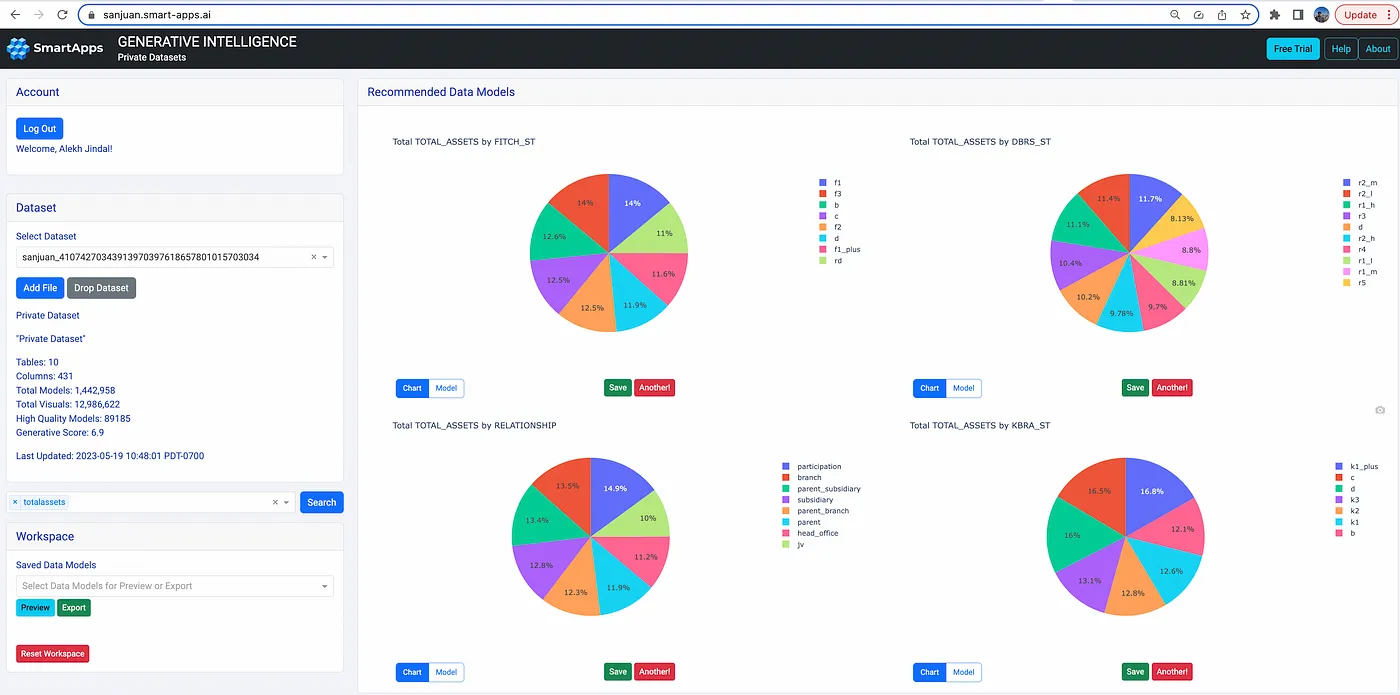
Finance Regulation (FIRE) Data Standard
Financial data can be messy and there is a need to standardize by harmonizing data from various sources into a common model. Suade has come up with one such data model, called FIRE. SanJuan can process data in FIRE schema and generate insights over assets, ratings, encumbrance, balance, interest, and others.
KDD Cup 2023
SIGKDD runs the KDD Cup every year, and this year’s challenge is to recommend the next product for an e-commerce store. Such an exercise requires exploratory data analysis (EDA) as a first step, where the data scientist sees what’s in the data and how different variables relate to each other. SanJuan can help data scientists do such an analysis by quickly generating insight and providing them a way to understand data before they build their ML models.

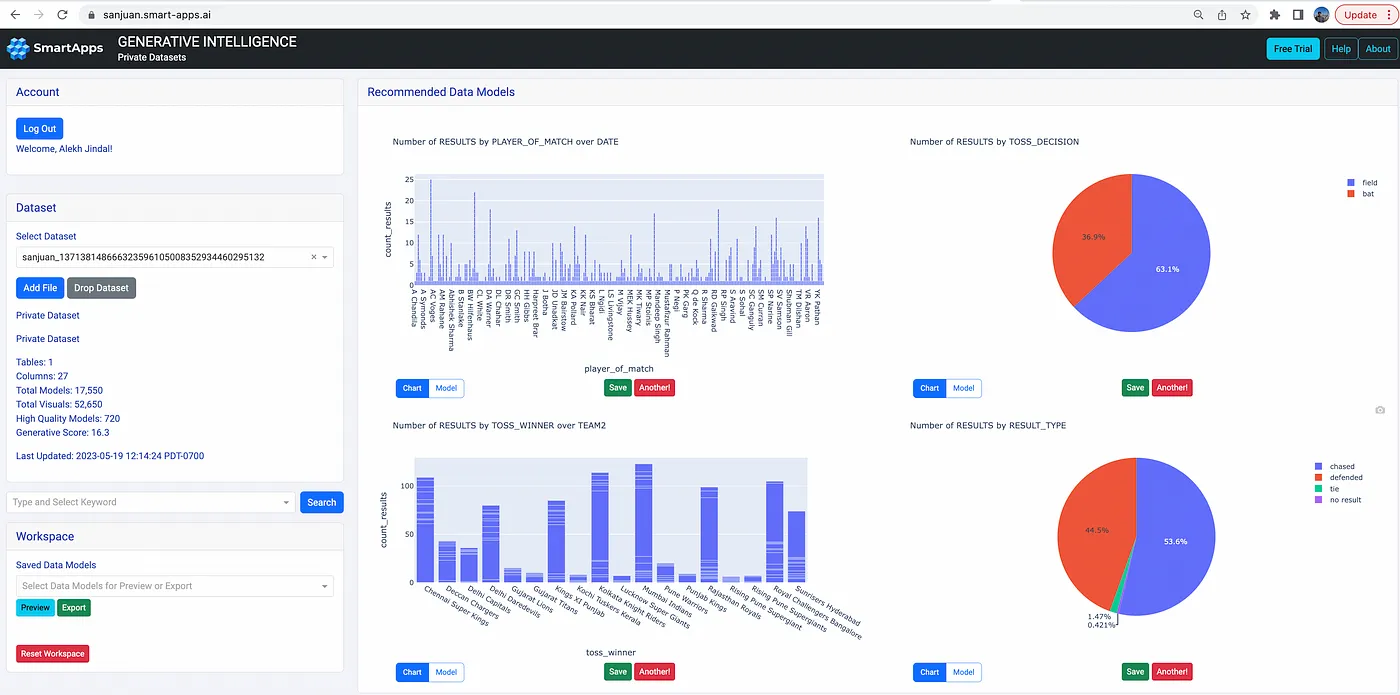
Indian Premier League (IPL)
The Indian Premier League for Cricket has emerged as the second-richest sports league in the world, behind only the NFL. Fans and advertisers are looking for newer ways to analyze the game and its related statistics. SanJuan can help analysts surface interesting insights. For example, match data from 2008–2022 shows that while 63% field first yet only 53% are able to chase, or that Mumbai has hosted 2x the number of matches than other cities, or that the number of matches per season has varied over the years.
The Beginnings
Data has become the mainstay of modern enterprises. And with newer advances in AI, enterprise data has the potential to take any business to the next level. However, this data needs to be transformed into models that could be consumed by the fast-growing intelligent apps. With “large data model” (LDM), our goal is to make data transformation automated in every organization, thus unlocking the business value quickly. However, just like the early chess-playing machines, LDM still has a long way to go; with enough iterations, we hope to one day turn any data into self-serving intelligence for stakeholders to address their business needs — this is our mission at SmartApps!
Related blog posts

Analyzing MCP Token Costs
MCP token costs depend more on architecture than on which LLM you pick — a comparative analysis and a forecasting tool to understand token costs better.
Read more

The Context Structuring Problem
Enterprise AI is only as good as its context — but today that context is scattered across prompt files, skill markdowns, and ad hoc RAG pipelines that every team rebuilds from scratch.
Read more

Making MCPs Practical with Context Pushdown
Traditional MCPs have a twist the moment you try to run them in production: they can be unreliable, expensive, and slow.
Read more
Bring search to your
workflows
workflows
See how Tursio helps you work faster, smarter, and more securely.


Data protection
'/%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_7851_102227'%20x1='0'%20y1='174.933'%20x2='1312'%20y2='174.933'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%231E4EC4'/%3e%3cstop%20offset='0.8'%20stop-color='%230D6EFD'/%3e%3cstop%20offset='1'%20stop-color='%235BC0EB'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)