

Models
Evaluating Reasoning Models
Published: January 21, 2026
Share this post

Large language models have become the powerhouses of reasoning. OpenAI's o1 was the first reasoning model to automate chain-of-thought reasoning for logical and mathematical tasks. Many other models have excelled in complex deductive, inductive, or multi-step reasoning tasks since then.
Tursio uses reasoning models to generate a response summary for the user's question, given the data retrieved from the structured data source. This summary is intended to provide a deeper insight into the data. In this blog, we discuss an evaluation of various reasoning models to generate a high-quality summary for the user. We evaluated the following reasoning models:
These dimensions are complementary and together provide a comprehensive view of summary quality.
Your evaluation must map to one of the following overall quality categories:
When grading, assess the summary on the following dimensions:
You will provide:
Question: {question}
Generated Summary: {generated_summary}
Respond **only** in valid JSON:
{{ "score": <Quality category>, "justification": "<short reasoning>" }}
Response must be in a JSON format.
Each categorical label is mapped to a numerical score using a fixed scale.
{ 'excellent':1, 'good':2, 'average':3, 'poor': 4 }
For every summary, each model independently produces a categorical rating and a short justification. We convert the categorical rating to a numeric score using the scoring map. We finally report the average of their individual scores as the final score representing the quality of the generated summary.

Overall, Tursio generates high-quality responses to user questions. These responses are critical for non-expert users to understand the final answer, without requiring them to dig into the details. Although the response times are interactive, the response quality still has room to improve further. We expect a combination of model advancements and prompt engineering to improve the scores further.
Tursio uses reasoning models to generate a response summary for the user's question, given the data retrieved from the structured data source. This summary is intended to provide a deeper insight into the data. In this blog, we discuss an evaluation of various reasoning models to generate a high-quality summary for the user. We evaluated the following reasoning models:
- o3-mini
- o4-mini
- haiku-4.5
- Gemini-2.5-pro
- Gemini-3-pro-preview
Defining quality for a summary
To evaluate a summary effectively, we choose dimensions that capture both how well the content is conveyed and how appropriately it is presented. We define the “Quality” of the summary generated along the five dimensions - clarity and coherence, conciseness, structure, factuality, and length appropriateness.These dimensions are complementary and together provide a comprehensive view of summary quality.
- Clarity & Coherence: This ensures that the summary is easy to understand and that ideas flow logically from one to the next. A summary that is unclear or disjointed, even if factually correct, fails its primary purpose of helping the reader quickly grasp the main points.
- Conciseness: A good summary should capture the essential information using as few words as necessary, avoiding redundancy, filler, or verbose explanations. Overly long or repetitive summaries dilute the key insights and impose unnecessary cognitive load on the reader. By explicitly evaluating conciseness, we reward summaries that prioritize signal over noise while still remaining complete enough to be useful.
- Structure: Structure focuses on the organization of ideas: whether the summary has a logical beginning, middle, and end, and whether related points are grouped meaningfully. A poorly structured summary can be hard to follow and should be penalized.
- Factuality: Factual correctness is critical: a summary that misrepresents, omits, or invents key facts undermines trust and can lead to incorrect conclusions. Especially for automatically generated summaries, there is a risk of hallucinations or subtle distortions of the source material. Evaluating factuality ensures that high-scoring summaries remain faithful to the original content and do not introduce misleading information.
- Length Appropriateness: The “right” length for a summary depends on the nature and complexity of the underlying content and the task: open-ended, nuanced inputs warrant longer summaries, while direct, focused questions should yield shorter ones. By assessing length appropriateness, we align the output with user expectations and task requirements, rewarding summaries that balance brevity with sufficient detail.
Ensemble-LLM-as-a-grader
To assess the quality of automatically generated summaries, we use an Ensemble-LLM-as-a-grader evaluation protocol. An ensemble of models reduces individual bias compared to a single model. We used GPT-4.1, GPT-5.1, and Haiku-4.5 as graders. These models independently judge the response, and their scores are aggregated.Grading rubric
Below, we first describe our prompt and scoring function before showing the results.Prompt
"You are an expert evaluator tasked with grading the quality of an automatically generated summary."Your evaluation must map to one of the following overall quality categories:
- Excellent - perfectly concise, clear, structured, factual, and of appropriate length
- Good - mostly structured minor issues in clarity, conciseness, or length
- Average - partially clear, coherent
- Poor - significant clarity issues, not following any structure, incoherent
When grading, assess the summary on the following dimensions:
- Clarity & Coherence - Is the summary easy to understand and logically structured?
- Conciseness - Is the summary free of unnecessary repetition or verbosity?
- Structure - Is the ordering of ideas appropriate and helpful for comprehension?
- Factuality - Are all facts, claims, and relationships represented?
- Length Appropriateness - Is the length reasonable for a summary of this content? For open-ended questions, the expected length is large. For to-the-point questions, the expected length is short.
You will provide:
- A **Quality Category** (Excellent, Good, Average, Poor).
- A **brief justification** (1–3 sentences) explaining the main reasons for the score.
Question: {question}
Generated Summary: {generated_summary}
Respond **only** in valid JSON:
{{ "score": <Quality category>, "justification": "<short reasoning>" }}
Response must be in a JSON format.
Scoring
The grader is provided with a structured rubric that categorizes each summary into one of four quality levels: Excellent, Good, Average, or Poor.Each categorical label is mapped to a numerical score using a fixed scale.
{ 'excellent':1, 'good':2, 'average':3, 'poor': 4 }
For every summary, each model independently produces a categorical rating and a short justification. We convert the categorical rating to a numeric score using the scoring map. We finally report the average of their individual scores as the final score representing the quality of the generated summary.
Summary of results
- The summary quality evaluation via Ensemble-LLM grading scores 1.87, indicating high-quality structured summaries.
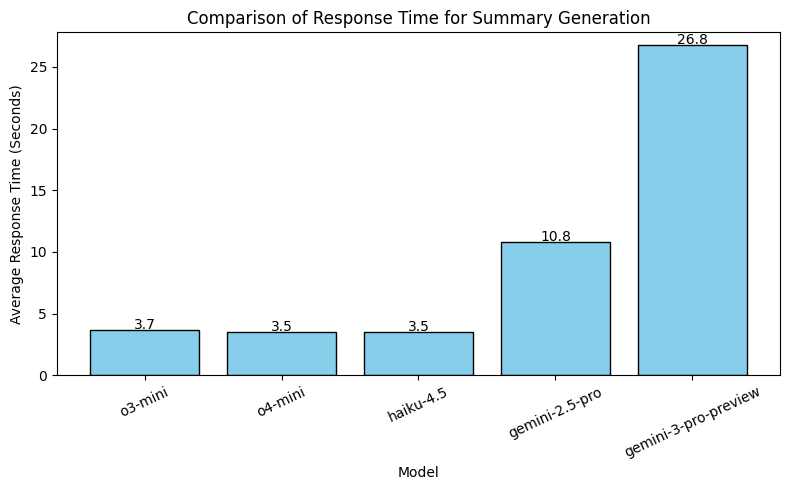
- o4-mini and haiku-4.5 produced better-quality summaries.
- On average, haiku-4.5 and o4-mini were the fastest. These response times exclude streaming. In practice, response times are lower due to streaming.
Overall, Tursio generates high-quality responses to user questions. These responses are critical for non-expert users to understand the final answer, without requiring them to dig into the details. Although the response times are interactive, the response quality still has room to improve further. We expect a combination of model advancements and prompt engineering to improve the scores further.
Related blog posts

Analyzing MCP Token Costs
MCP token costs depend more on architecture than on which LLM you pick — a comparative analysis and a forecasting tool to understand token costs better.
Akshara Mahalingam and Shivani Tripathi
Read more

The Context Structuring Problem
Enterprise AI is only as good as its context — but today that context is scattered across prompt files, skill markdowns, and ad hoc RAG pipelines that every team rebuilds from scratch.
Alekh Jindal
Read more

Making MCPs Practical with Context Pushdown
Traditional MCPs have a twist the moment you try to run them in production: they can be unreliable, expensive, and slow.
Shivani Tripathi, Wangda Zhang, Alekh Jindal
Read more
Bring search to your
workflows
workflows
See how Tursio helps you work faster, smarter, and more securely.


Data protection
'/%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_7851_102227'%20x1='0'%20y1='174.933'%20x2='1312'%20y2='174.933'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%231E4EC4'/%3e%3cstop%20offset='0.8'%20stop-color='%230D6EFD'/%3e%3cstop%20offset='1'%20stop-color='%235BC0EB'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)