

Token Cost
Analyzing MCP Token Costs
Published: June 19, 2026
Share this post

The rise of MCPs
More products now let users query their data in plain language. Someone asks, "Why did revenue drop last quarter?" or "Which dormant accounts hold additional inactive products?", and the system must turn that into SQL and run it. The standard way to wire this up is an MCP (Model Context Protocol) server, which sits between the LLM and the database and handles schema discovery, query execution, and result interpretation.Every major AI tool, including Claude, ChatGPT, Copilot, and Teams, now supports MCP servers as tools, invoked either explicitly by the user or implicitly during a conversation. That puts live data access in the hands of business users and agents within the tools they already work in. But as usage scales, so does the cost, and it adds up faster than most teams expect.
Two Architectures
The instinct is to blame the model: GPT-5.4 versus GPT-4.1 versus something smaller. But while benchmarking several vendor-provided MCP servers — including SQL Server, Snowflake, Supabase, and MotherDuck — we found the server's own architecture often mattered more. Interestingly, the default MCP servers let the agent on top drive schema discovery and query generation, so the same database gets rediscovered and reinterpreted on every query. Tursio instead pushes that work down into a shared context that all queries and agents reuse. The figure below compares these two design choices: dynamically inferring transient context for each request versus pushing it down as a shared, persisted context.
This blog compares these two architectures in terms of cost. We focus on SQL Server as the baseline and use its default MCP server for comparison. Given the widespread use of SQL Server for critical workloads, we expect cost to be an important factor and measure it across questions of varying difficulty. Building on the results, we then share an estimator that predicts MCP cost before a query ever runs.
The Evaluation Setup
We consider the default SQL Server MCP server as the baseline for this evaluation. Specifically, we used the Azure-Samples/SQL-AI-samples Node.js implementation. It was originally designed for local development, so we made the necessary changes to expose it as an HTTP-streamable server for remote client integration with ChatGPT.We compared this default MCP with Tursio MCP’s pushdown architecture, testing across 192 analytical queries spanning a banking dataset for credit unions. For each query, we tracked input tokens, output tokens, tool calls, SQL complexity, latency, and estimated cost.
We divided the test bed into two types of questions: direct vs generic, meaning specific questions like "List members with deposits over $2,000" against more open, and sometimes even ambiguous, ones like "How users are assigned to each branch location". These two sets of questions were further subdivided into easy, medium, and hard, based on the amount of reasoning required for each query.
The key metric for us was how much reasoning work each architecture pushed into the LLM.
Costs can be very different
Cost was the first thing on which the two architectures diverged. The figure below shows the dollar cost of running queries under each. On the banking dataset, SQL Server costs about $45 per thousand direct queries, while Tursio costs about $12. On generic queries, the gap widened: SQL Server climbed to $80, while Tursio stayed under $20 — roughly 72 to 75% cheaper across both query types.
Data reasoning effort drives the cost
To see why, we looked at the execution traces, and one number stood out: tool calls. SQL Server averaged about 8 per query. Tursio averaged 1.3. Every additional tool call brings more schema context and intermediate results back through the model, and all of it becomes tokens.The SQL itself told the same story. SQL Server generated queries with around 6 JOINs on average for semantic understanding. Tursio generated just two. Tursio resolves more context before SQL generation, while SQL Server pushes more of that work into the LLM during generation. The figure below breaks down the dollar cost into tokens, latency, and tool calls -- clearly showing that the default MCP servers end up doing far more total work.

That architectural difference is the main driver of the cost gap.
Ambiguous Questions Make It Worse
Real users don't write clean queries. They ask things like "How are inactive customers behaving?", questions that need interpretation before they can be answered.Both systems got more expensive on these ambiguous queries. We called this the generic query tax. Both systems paid a similar percentage penalty, but SQL Server's absolute dollar increase was about five times larger. We can see that the architectural inefficiency compounds when user intent gets messy.
Harder Queries Make It Worse, Too
The gap widened as queries became more complex.SQL Server: easy queries about $24 per thousand, hard queries almost $77. A 3.3x jump. Tursio: $13 easy, $22 hard. A 1.6x jump.
The flatter curve matters because production workloads aren't static. A system that looks affordable during testing can get expensive once users start asking harder questions.

Predicting Cost Before Execution
The above results naturally lead us to the following question: If architecture drives cost so strongly, can we estimate cost before a query runs?We trained Ridge regression models using only pre-execution features: query intent, complexity, expected result size, dataset, and server type. Eight models total, one per server per token type, splitting input from output predictions because they're driven by different things.
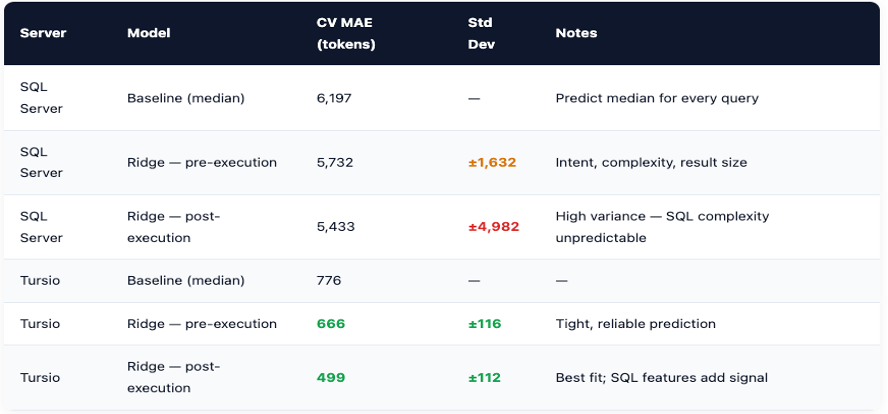
For Tursio, the pre-execution model has an MAE of 666 tokens and a standard deviation of ±116. The baseline of just predicting the median was 776. Tight and meaningfully better than guessing.
For SQL Server, the same approach was much noisier. MAE of 5,732 tokens pre-execution, and even adding post-execution SQL features only got to 5,433 with ±4,982 standard deviation. The error and the noise around it were the same size.
This makes sense structurally. SQL Server's costs depend heavily on SQL complexity that only emerges during execution. Tursio's architecture absorbs that variance upfront, so a small regression model can fit it well. The properties that make Tursio cheaper also make it easier to forecast.
Methodology
A few notes on the above analysis.We removed outliers using IQR per server and category, which dropped 24 of 192 rows (about 13%), mostly timeouts and unusual failure modes. Each query was run thrice per server, where possible, and we collapsed to medians to prevent the model from seeing both runs of the same query in both the train and test sets.
We benchmarked Ridge against a lookup table (server x category x complexity, no learning), which already hit R²=0.42. Ridge improves on that, but not dramatically. More data would help more than a fancier model.
Limitations worth flagging: The SQL Server prediction model is noisy enough that we wouldn't deploy it as-is. And this study doesn't score answer accuracy. We tracked whether servers returned responses, not whether the responses were correct. That's a separate evaluation.
The Estimator
Based on the analysis above, we built an MCP Cost Estimator. It takes a natural-language question and predicts intent, complexity, expected token usage, and estimated cost across MCP architectures, before the query runs.For example, given "What percentage of dormant accounts have additional products that are also inactive?", the estimator classifies the question, predicts token consumption, and estimates cost per server.

The goal isn't perfect prediction. It's giving teams visibility into cost before an agent starts generating SQL, calling tools, and burning tokens.
Takeaways
A few things stuck with us after this project.Tool calls are a meaningful cost driver, often more than model choice. Architectures that push more reasoning into the LLM generate higher and less predictable bills. Architecture that resolves more context before SQL generation stays cheaper and more stable across complexity and ambiguity.
For teams building natural language interfaces to data, the operating question may shift from "Which LLM should we use?" to "How much work are we asking that LLM to do?".
Related blog posts

The Context Structuring Problem
Enterprise AI is only as good as its context — but today that context is scattered across prompt files, skill markdowns, and ad hoc RAG pipelines that every team rebuilds from scratch.
Read more

Making MCPs Practical with Context Pushdown
Traditional MCPs have a twist the moment you try to run them in production: they can be unreliable, expensive, and slow.
Read more

Managing Ambiguities in Context Graphs
Agents are the new apps. Agents are quickly becoming the new apps. Instead of navigating complex software interfaces, users are increasingly interacting with AI agents that understand intent, retrieve information, and take action on their behalf. And one of the most compelling things you can do with an agent is connect it directly to operational databases, as seen in the recent move by Google to connect all their operational databases to MCPs.
Read more
Bring search to your
workflows
workflows
See how Tursio helps you work faster, smarter, and more securely.


Data protection
'/%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_7851_102227'%20x1='0'%20y1='174.933'%20x2='1312'%20y2='174.933'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%231E4EC4'/%3e%3cstop%20offset='0.8'%20stop-color='%230D6EFD'/%3e%3cstop%20offset='1'%20stop-color='%235BC0EB'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)