

Engineering
A “large data model” for Snowflake Data Marketplace
Published: April 6, 2023
Share this post

Recap: In the last post, we explored the question of whether data models can be learned for providing quick answers to data questions. In this post, we take a step forward to evaluating its feasibility on the Snowflake data marketplace.
The rise of cloud data warehouses has made it extremely easy to share and process data on demand. Today, anyone can get access to the most sophisticated query processors on the planet and start performing complex data transformations within minutes. No wonder there is a shift from traditional ETL style design to newer ELT or zero-ETL styles, where transformations happen once the data has already landed in the data warehouse. Thereafter, the onus is on the data analyst or the analytics engineer to create the right set of data transformations that can power the business apps. To understand how AI/ML can help in this process, let’s use data marketplaces as a concrete example below.
Snowflake Data Marketplace
The data marketplace concept has been around since early 2000s, with data.gov releasing in 2009 and Snowflake announcing its data marketplace a decade later in 2019. Since then, nearly all cloud vendors have launched their own marketplaces, including AWS, Azure, Google, and Databricks. Snowflake, in particular, has made it very easy for data providers and consumers to share and consume data. Thanks to its disaggregated storage and compute architecture, Snowflake users only pay for the compute they do over the shared data. Many large organizations also have similar shared data platforms internally, e.g., the Cosmos big data platform at Microsoft. Industry trends show that data marketplace platforms are fast growing, and it is expected to be a $5B+ market by 2030.
Typically, a data analyst starts by running sample queries like “Select * from T limit 10” to understand the data, before crafting the right data transformations and models. This means spending an inordinate amount of time hammering the data before getting to the actual insights part and iterating this process over and over again to meet the business requirements. For instance, consider the Amazon Vendor Analytics dataset on Snowflake marketplace that contains 52 tables and 1,568 columns. Such a dataset will require a significant amount of analyst time before it could be turned into intelligence. Instead of running the entire data marathon first, data analysts rather want to see things quickly and then shoehorn the data based on what they want.
Introducing PikePlace: Seeing is Analyzing

Pike Place Market Entrance by Mtaylor444. CC BY-SA 3.0
We present PikePlace, the first “large data model” for the Snowflake data marketplace. Just like the Pike Place Market that delights curious visitors, our goal is to get analysts the data models they need to power their business apps. Once the analyst connects to their data source, instead of messing with SQL queries, PikePlace shows them a set of generated data models to explore, search, refine, and ultimately operationalize. The following screenshot shows what an analyst sees when connecting to the same Amazon Vendor Analytics dataset in the Snowflake marketplace:
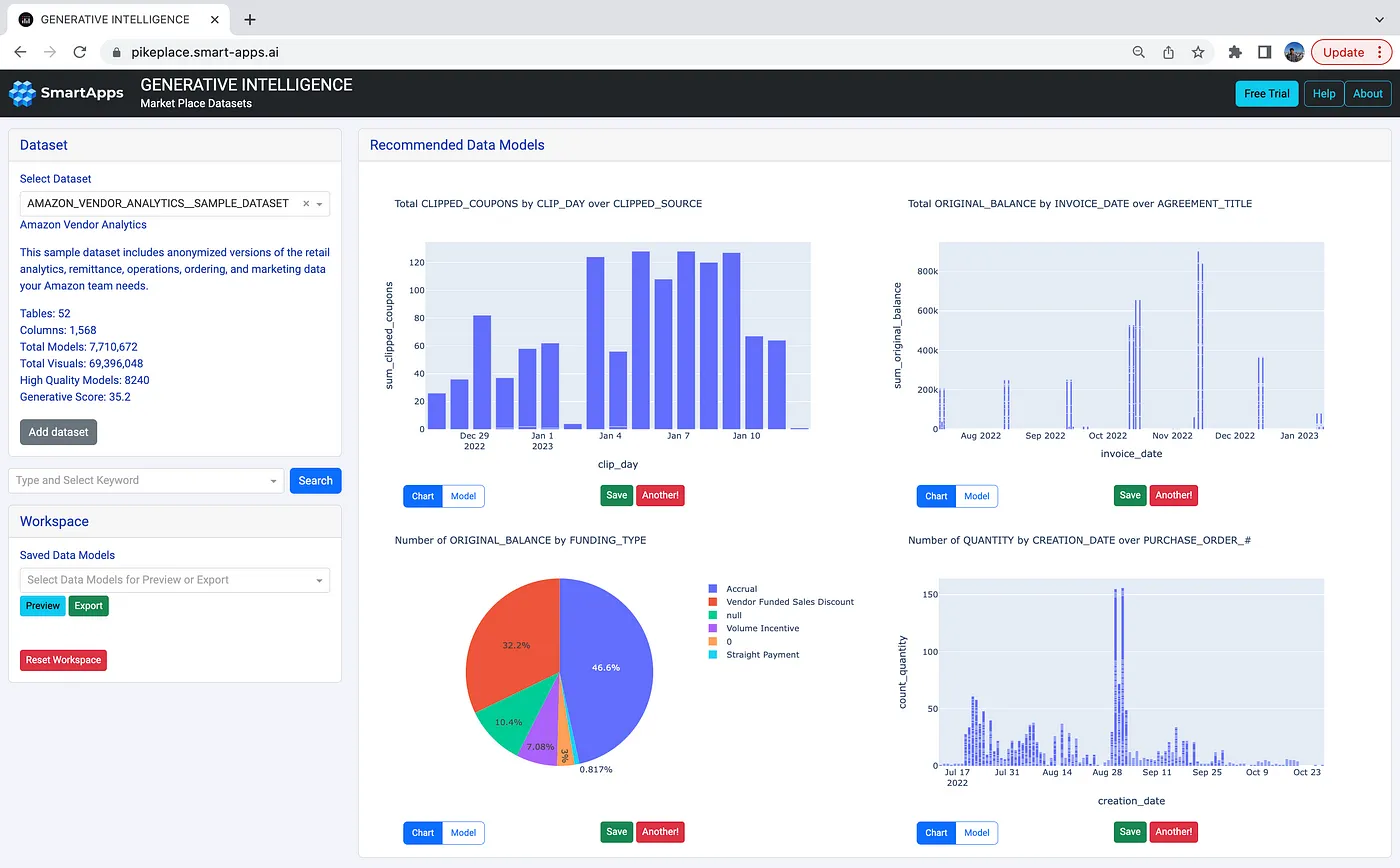
The analyst gets to directly see interesting visualizations in a single click! They can play with the interactive charts or ask for other similar visualizations by clicking “Another”. They can also inspect the data model by clicking the model tab, which shows the SQL statement, its natural language explanation, a model score, and a declarative syntax to plot the visualization, as illustrated in the screenshot below:
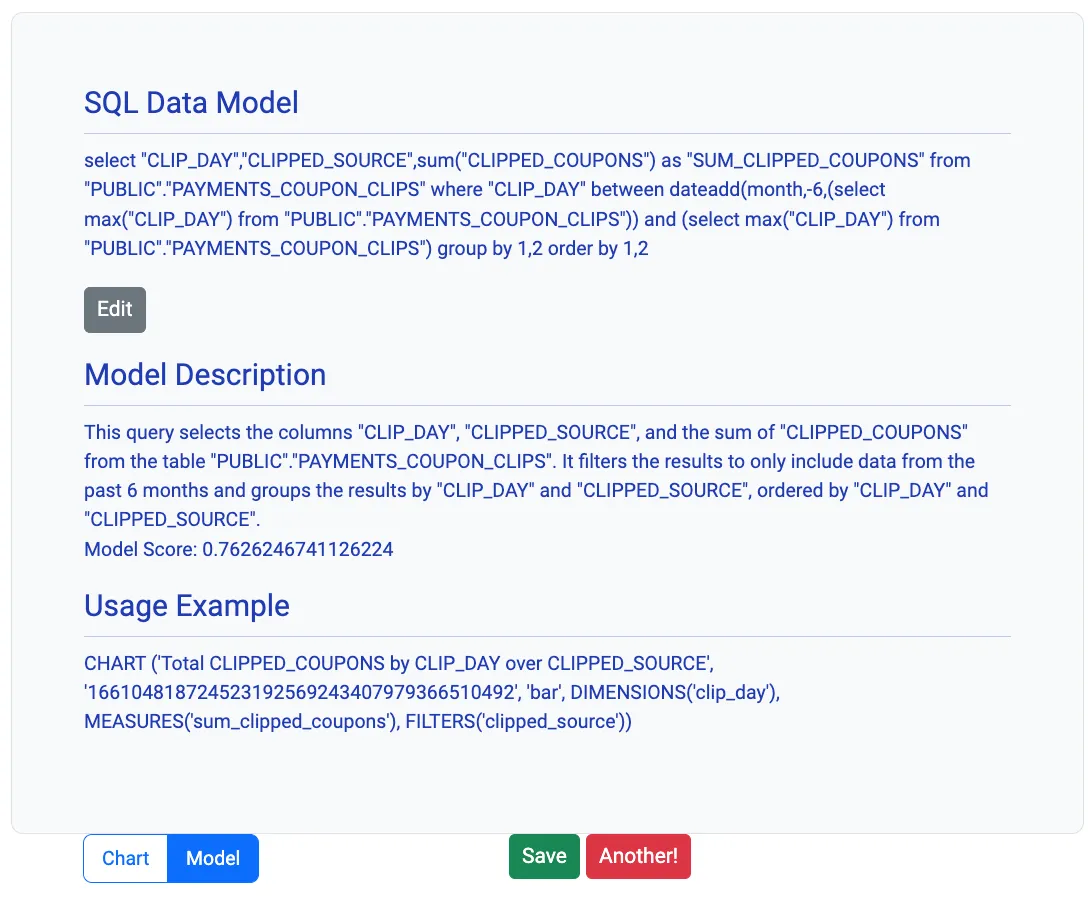
Analysts can refine models and collect all interesting ones into the workspace by clicking the “Save” button. They can preview saved models (across datasets) and export them into scalable workflows to keep them updated. The entire process is insights-first with all data shoehorning happening later, thus bringing in several key advantages:
- Reduces the time to insights by helping analysts discover and deliver the right data models to power business apps quickly.
- Enables anyone with access to data to start analyzing immediately without waiting for data engineers to craft the data for them.
- Optimizes data better using machine learning, thus providing interactive data exploration at much lower cost.
Generating Data Models: The Secret Sauce
The secret sauce in PikePlace is how the systems learns to generate data models from a given data source. We apply three-fold criteria when learning what kind of data models to generate.
- Quality, i.e., a data model contains clean and meaningful data.
- Correctness, i.e., the data model is semantically valid and makes sense.
- Interestingness, i.e., a data model stands out in what it shows.
Our algorithms learn to generate data models that qualify these criteria in a three-step process, involving enumeration via hundreds of parameterized rules, evaluation over a variety of metrics, and feedback to tune and improve in response to real-time observations.
We have been training the “large data model” on Snowflake marketplace datasets over the last few months and have created a pre-trained version that can generate data models for several diverse datasets, including areas such as real estate, covid-19, economy atlas, economic indicators, work force, consumer engagement, and vendor analytics. We are further improving this version with more usage and feedback every single day. Still, the “large data model” is relatively small right now and will need a significant amount of training to generalize much further. Fortunately, the existence of large number of data marketplaces out there provides an excellent source of real-world datasets to train on. Like language models, we believe that with enough training and tuning, we can learn how to generate the most useful data models over any given data source — thus providing quick insights to anyone over any data.
A Challenging Road
We envision large data models to be a specialized AI system for solving a domain specific problem, with numerous customizations and retrofitting that are peculiar to the world of data modeling and transformations. Our early results on Snowflake marketplace are encouraging, but there is still a long road ahead. Just like the First Men, we hope the first “large data models” come riding horses, with bronze swords, and great leathern shields to change the world for the better.
Related blog posts

Analyzing MCP Token Costs
MCP token costs depend more on architecture than on which LLM you pick — a comparative analysis and a forecasting tool to understand token costs better.
Read more

The Context Structuring Problem
Enterprise AI is only as good as its context — but today that context is scattered across prompt files, skill markdowns, and ad hoc RAG pipelines that every team rebuilds from scratch.
Read more

Making MCPs Practical with Context Pushdown
Traditional MCPs have a twist the moment you try to run them in production: they can be unreliable, expensive, and slow.
Read more
Bring search to your
workflows
workflows
See how Tursio helps you work faster, smarter, and more securely.


Data protection
'/%3e%3c/g%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_7851_102227'%20x1='0'%20y1='174.933'%20x2='1312'%20y2='174.933'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%231E4EC4'/%3e%3cstop%20offset='0.8'%20stop-color='%230D6EFD'/%3e%3cstop%20offset='1'%20stop-color='%235BC0EB'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)